
│By Sarah L. Ketchley, Senior Digital Humanities Specialist│
One of six embedded tools in Gale Digital Scholar Lab, Named Entity Recognition (NER) processes Optical Character Recognition (OCR) text data and captures information about a range of words defined as ‘entities’, detailed below. The tool is ideally suited for text-based analysis, including text encoding and mapping. This blog post will discuss some of the highlights of the Lab’s NER tool, and things to bear in mind when creating an analysis configuration. We’ll finish with a couple of sample use cases to inspire your own NER analysis.
What is a Named Entity?
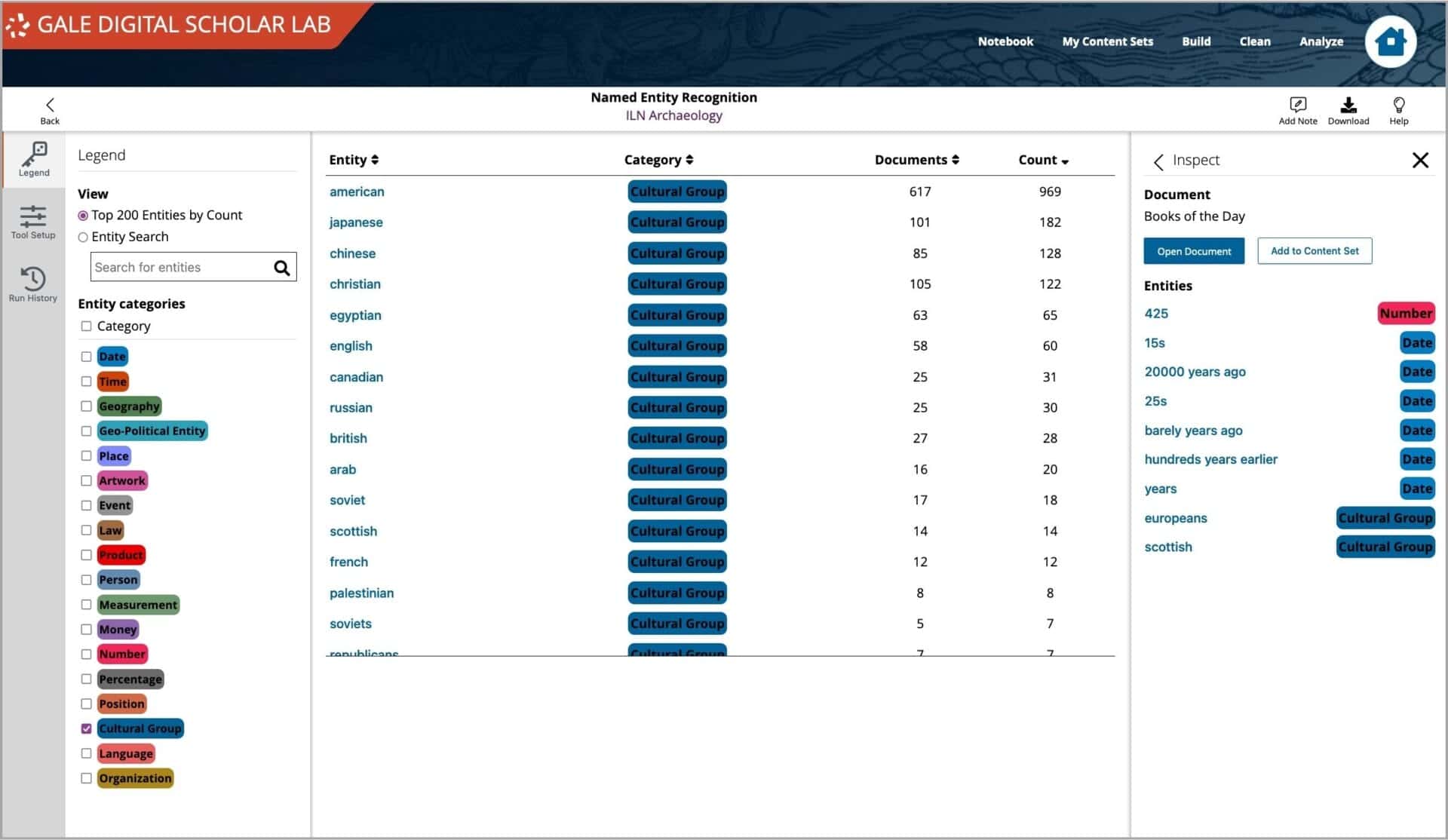
A named entity in a text is an object that’s assigned a name – for example, a person, a country, an organization, or a book title. The Named Entity Recognition tool in Gale Digital Scholar Lab does exactly that – it parses the texts in your content set to identify words that the model has identified as ‘entities’. NER in the Lab is based on the open source spaCy model, which has been trained using the OntoNotes 5 corpus. Here is the list of entities which will be recognized, along with their spaCy abbreviation and Gale name.
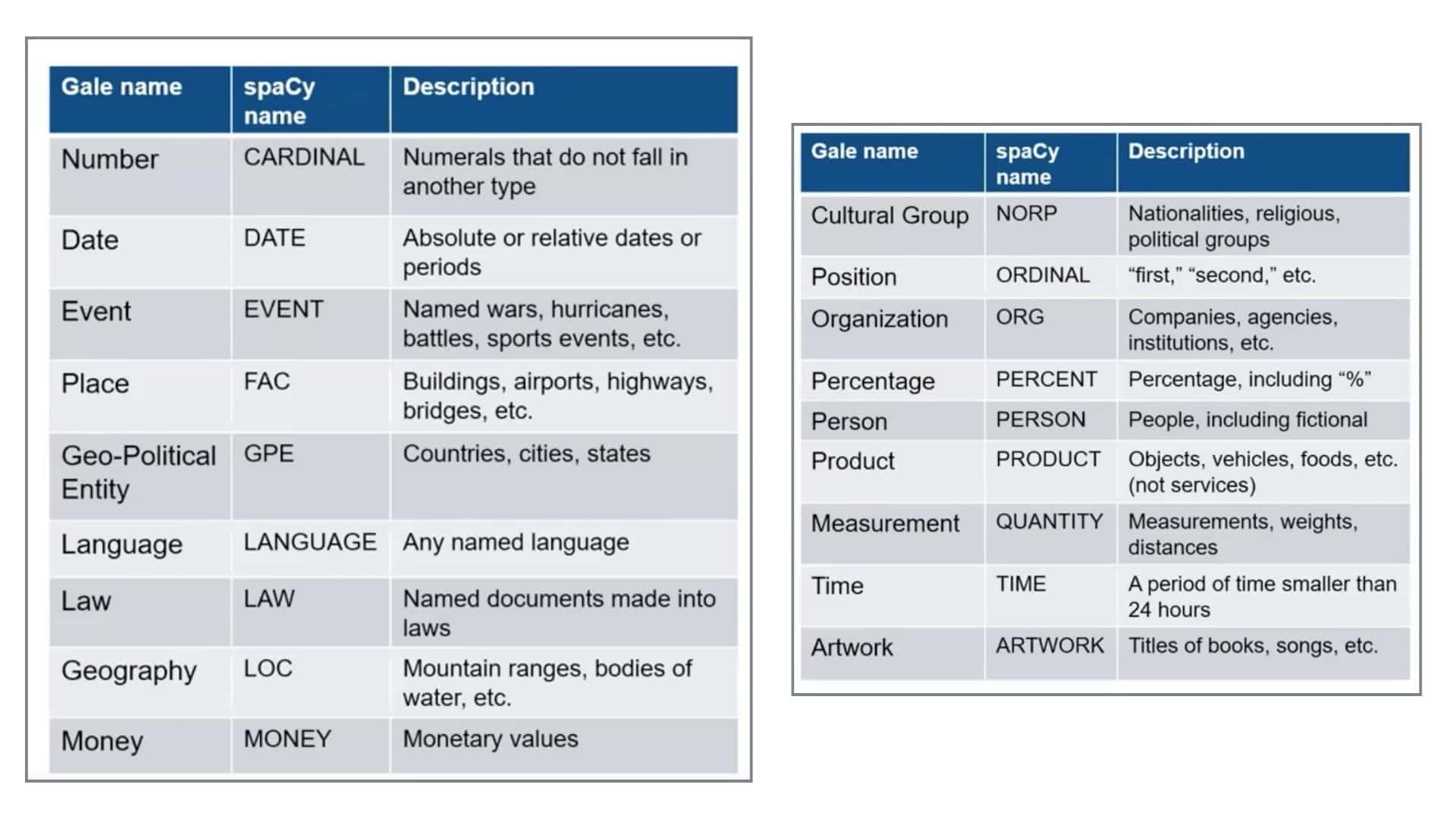
The spaCy algorithm works by asking the training model for a prediction, which is one of the reasons why the output may not be perfect, since it depends on the examples the data was originally trained on. Of course, the quality of the OCR text also plays an important role in generating accurate NER output. Cleaning and familiarization with content is an important stage of the analysis process.
The Case for Considering Case
The case of words (lower or upper) provides an important clue for the NER algorithm – words beginning with capitals are more likely to be proper nouns, for example. This is something to bear in mind when you’re creating a clean configuration. It’s best not to normalize the content set to all lower case. If you have a mixed set of upper- and lower-case spellings (e.g. ‘london’ and ‘London’), the tool will list them as separate entities. It’s also important to be aware that numbers are included in the default stopword list – ‘one’, ‘two’, ‘three’ etc. and these would otherwise be tagged as ‘number’ were they not removed.

Interpreting Output
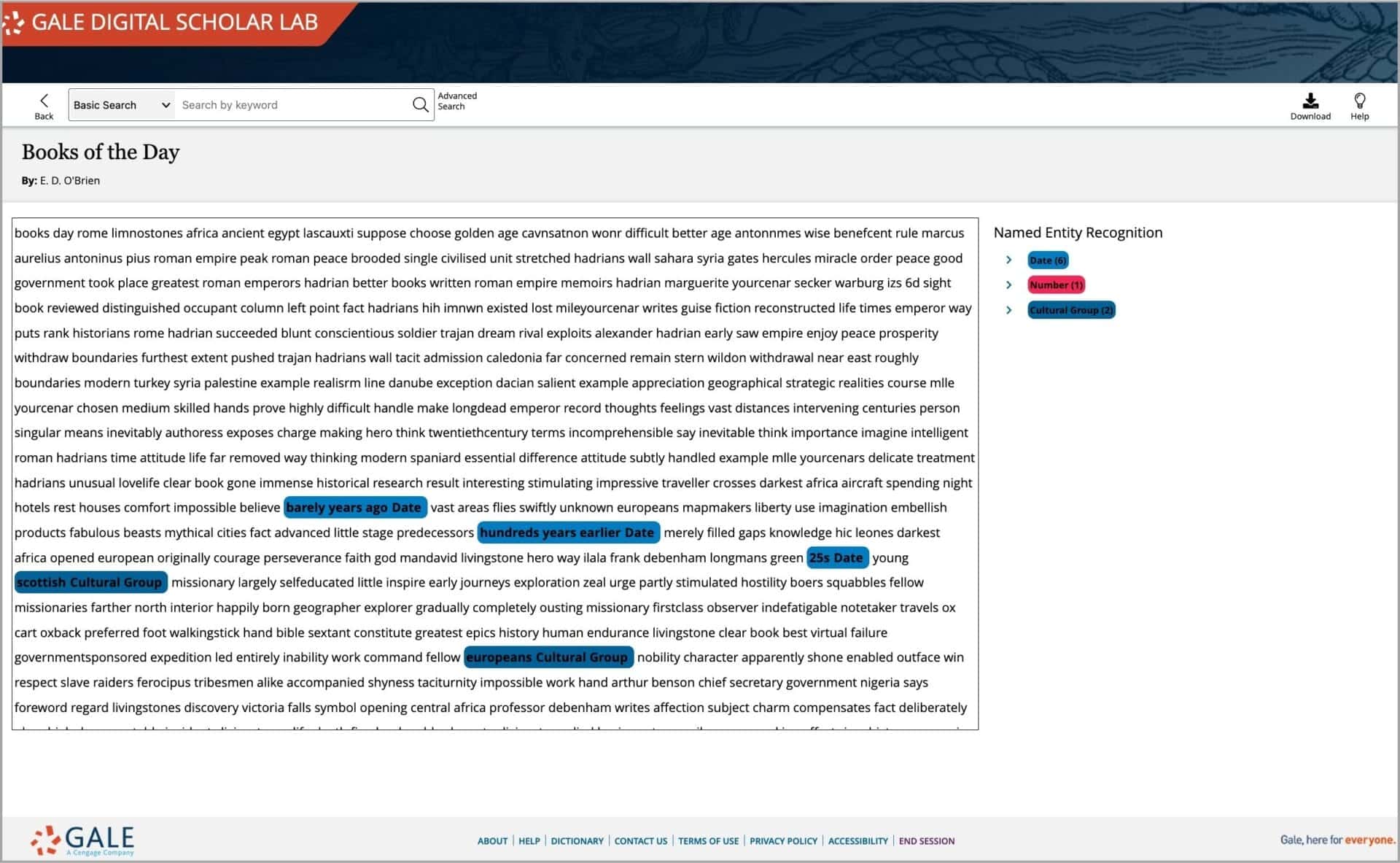
The Lab provides several pathways to filter, investigate, and download NER output. From the analysis results page, the researcher can filter by entity type, and dig into statistical data about the number of documents and counts for each entity term. Clicking on a specific entity name will open the inspect panel providing a list of documents the entity appears in, which can then be opened in a new window to see the entity within the context of its surrounding text.
Use Cases
Text Encoding and NER
The Emma B. Andrews Diary Project is long-running digital humanities project at the University of Washington, involving a collaborative group of undergraduate and graduate interns, under my direction. Our goals include the creation of immersive digital editions of unpublished diaries, correspondence, and other historical ephemera related to Nile travel and archaeology at the end of the nineteenth and beginning of the twentieth centuries. The editorial process involves transcription into plain text, encoding in XML-TEI, researching biographical details and sourcing images of historical figures, data management and public scholarship.
The team has developed a process to automate XML tagging, which includes named entity recognition. These named entities form the pathway for contextual analysis of primary source content. The image below shows an excerpt from one diary volume, with entities captured within XML tags. The Lab’s upload feature has also been valuable for importing project plain text documents for analysis using NER within the platform.

The entity tags in the encoded document are dynamically linked by a Google Apps script with a biographical database developed by the project team. The output is displayed in an online reader, created using TEI Publisher, below.

Mapping with NER
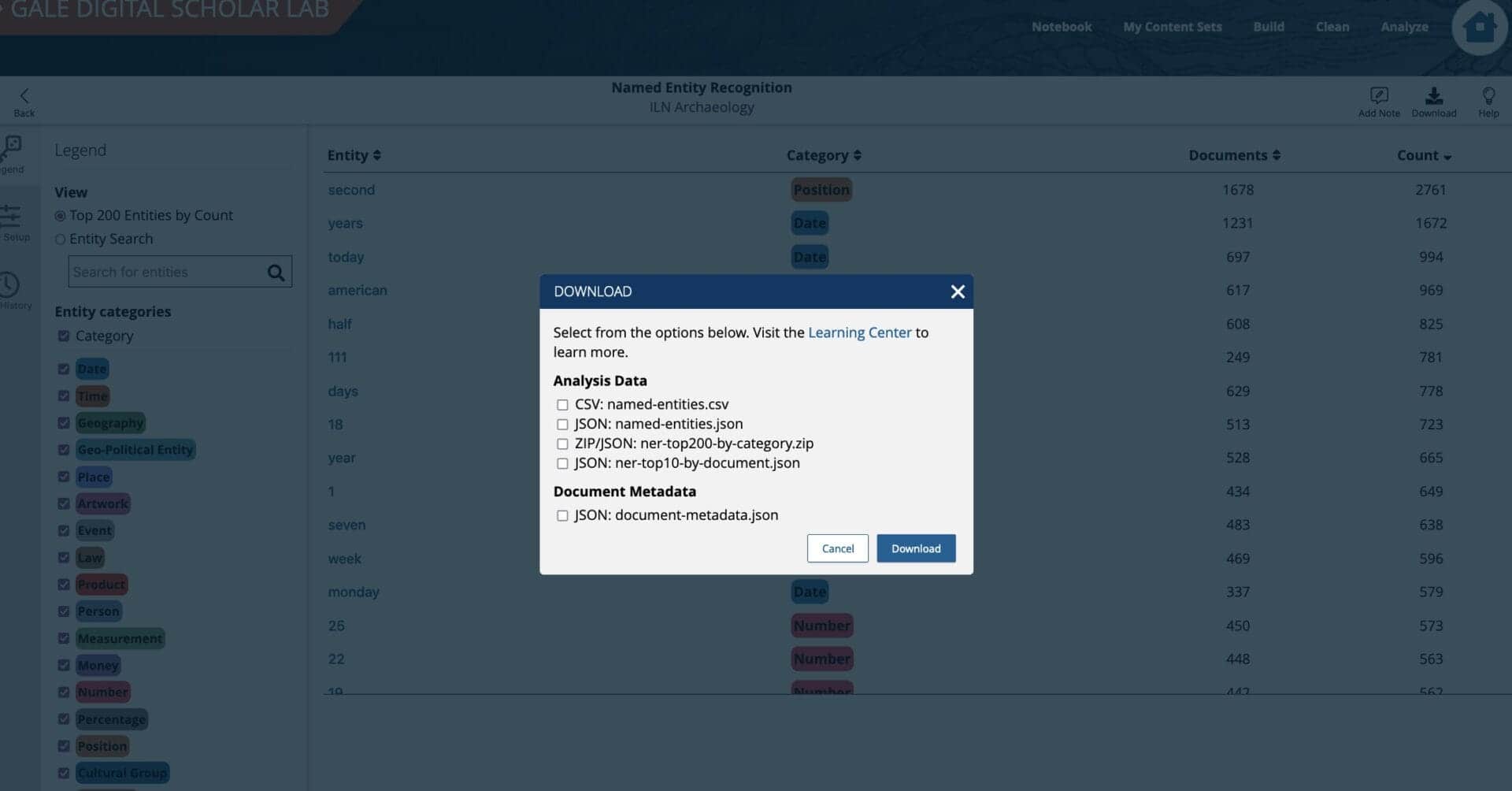
Processing temporal and geographical entities using the tool provides a pathway for building timelines and maps. The raw analysis data can be exported in CSV or JSON formats which can facilitate the process of geocoding geographical data.
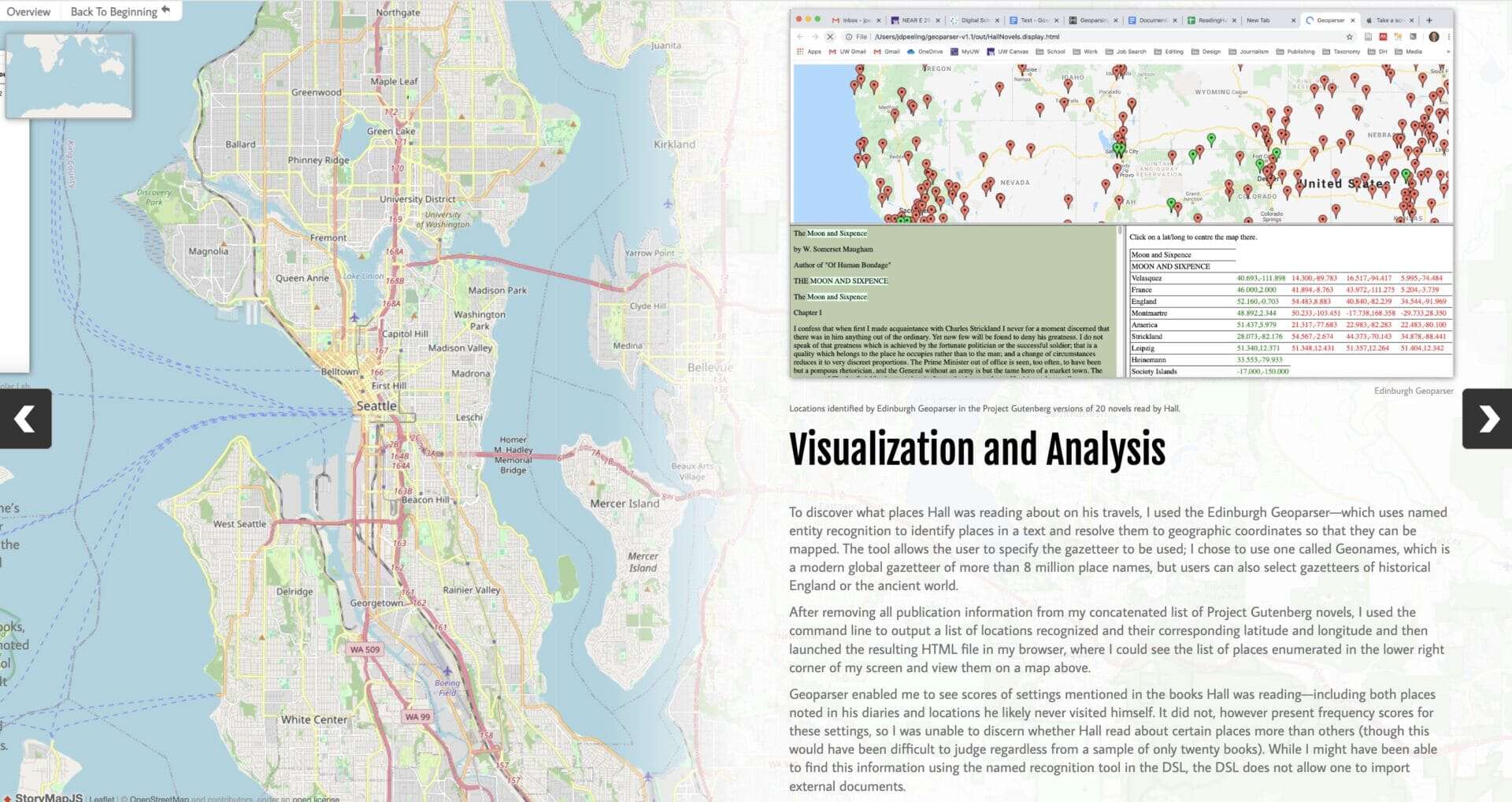
An example of this process in action is the Storymap “The Books He Carried: A Study of Lindsley Foote Hall’s Reading Habits on His Travels.” The text data used for initial research included a series of diaries kept by a draughtsman working in the Valley of the Kings, as well as a series of books that he read on his travels.

Named Entity Recognition (NER) was used in this project as a way of finding book titles, and geographic locations. This information was then exported and processed to generate a map of book titles detailed below. An integral part of this process was geocoding placenames exported from the Lab after running an NER analysis on the diary content.

The final map was built using the Edinburgh Geoparser, following the Programming Historian tutorial. If you want to learn more about working with StoryMaps, check out this blog post.
In Conclusion
As with all the tools in Gale Digital Scholar Lab, named entity recognition provides a rich environment for analysis of Gale Primary Sources and user-uploaded texts. It can also be used as a bridge for developing further research questions, by revealing content insights that are not immediately apparent using close-reading methodologies.
For an interactive demo and walkthrough of the NER tool, you may also find the NER Training Webinar valuable. An additional research project using NER, Lab export and Tableau visualization is explored in the blog post ‘Tracking Archaeology in The Illustrated London News’.
If you enjoyed reading this blog post, check out others in the ‘Notes from our DH Correspondent’ series, which include:
- Re-imagining Assignments in the DH Classroom II: Timelines, Digital Exhibits, and Maps
- Re-imagining Assignments in the DH Classroom: StoryMaps
- Understanding Recent Enhancements to Sentiment Analysis in Gale Digital Scholar Lab
{kind=link}