
│By Sarah L Ketchley, Senior Digital Humanities Specialist│
An integral part of the workflow of any digital humanities project involving text generated automatically by Optical Character Recognition (OCR) is the correction of so-called OCR errors. The process is also called ‘data cleaning’. This post will explore some of the considerations researchers should be aware of before starting to clean their data in Gale Digital Scholar Lab, using the built-in text cleaning tool. It will also offer additional resources for working with data in other formats outside of the Lab.

Structured and Unstructured Data
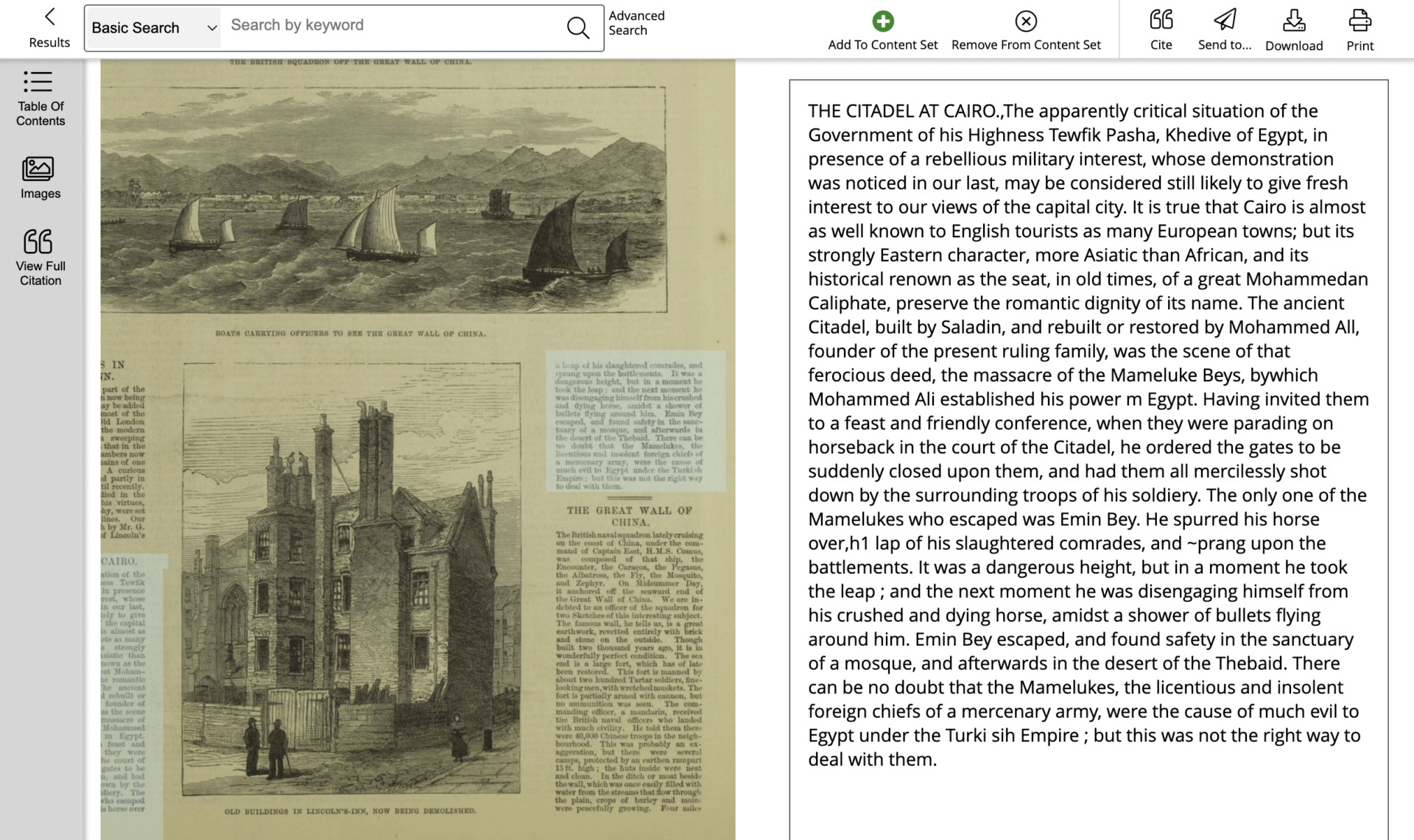
Deciding how to clean data begins with choosing an appropriate method based on the source data’s format. Structured data is often ordered in a spreadsheet and may also be referred to as tabular data. Unstructured data, as its name suggests, has no defined structure and is often plain text or images. The integral ‘Clean’ tool in Gale Digital Scholar Lab works with unstructured text data, generated by Gale during the OCR process and viewable in Gale Digital Scholar Lab. The image below shows the ‘Document Explorer’ view in the Lab, with the original image on the left, and OCR text output on the right.
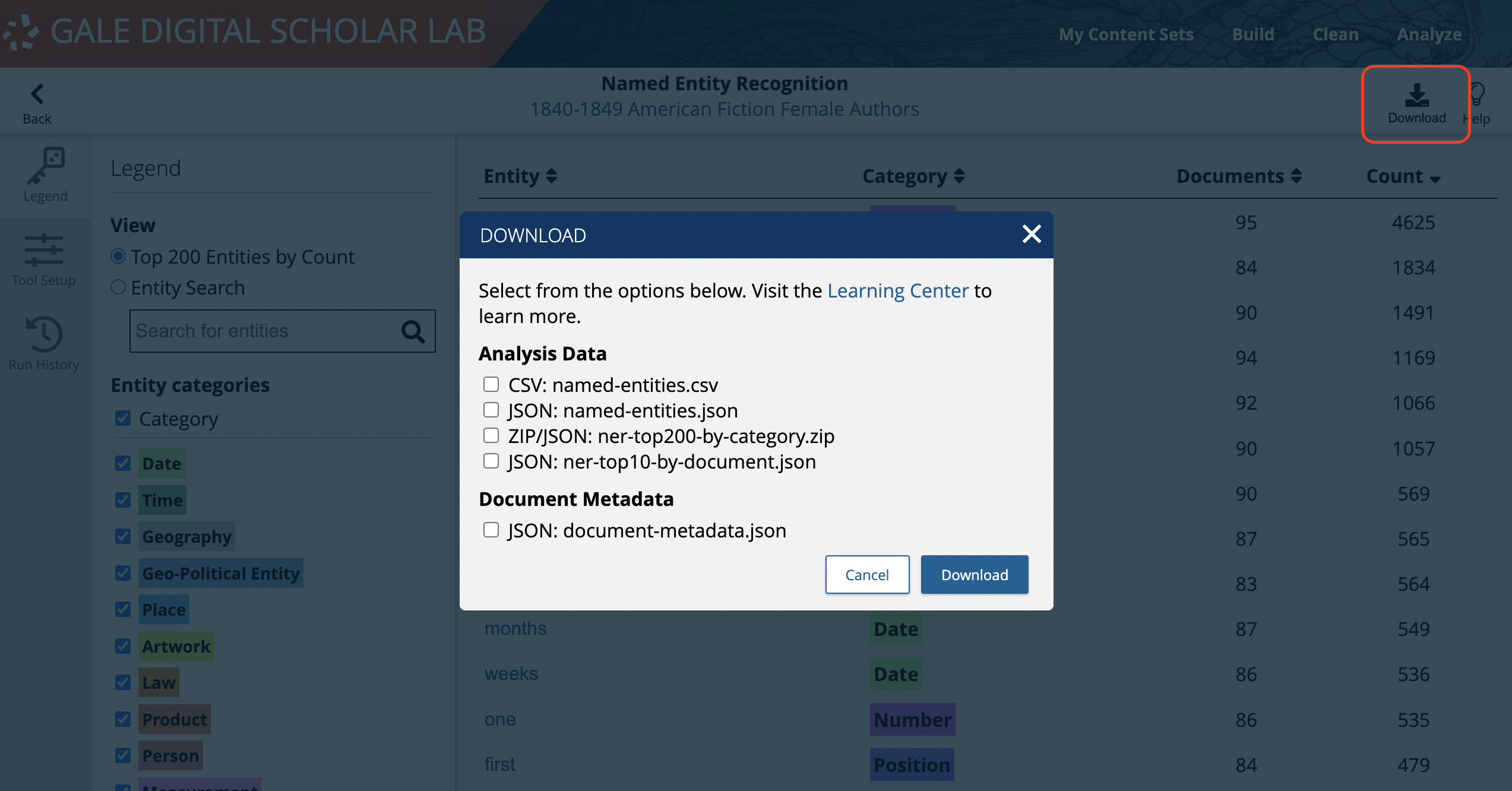
The Lab also provides a pathway for exporting structured data in the form of tabular downloads. Users can download the raw analysis data in various formats as well as a CSV of the full metadata from the Content Sets they build. This structured data can then be cleaned outside of Gale Digital Scholar Lab using tools like OpenRefine or regular expressions.
Cleaning Text in Gale Digital Scholar Lab
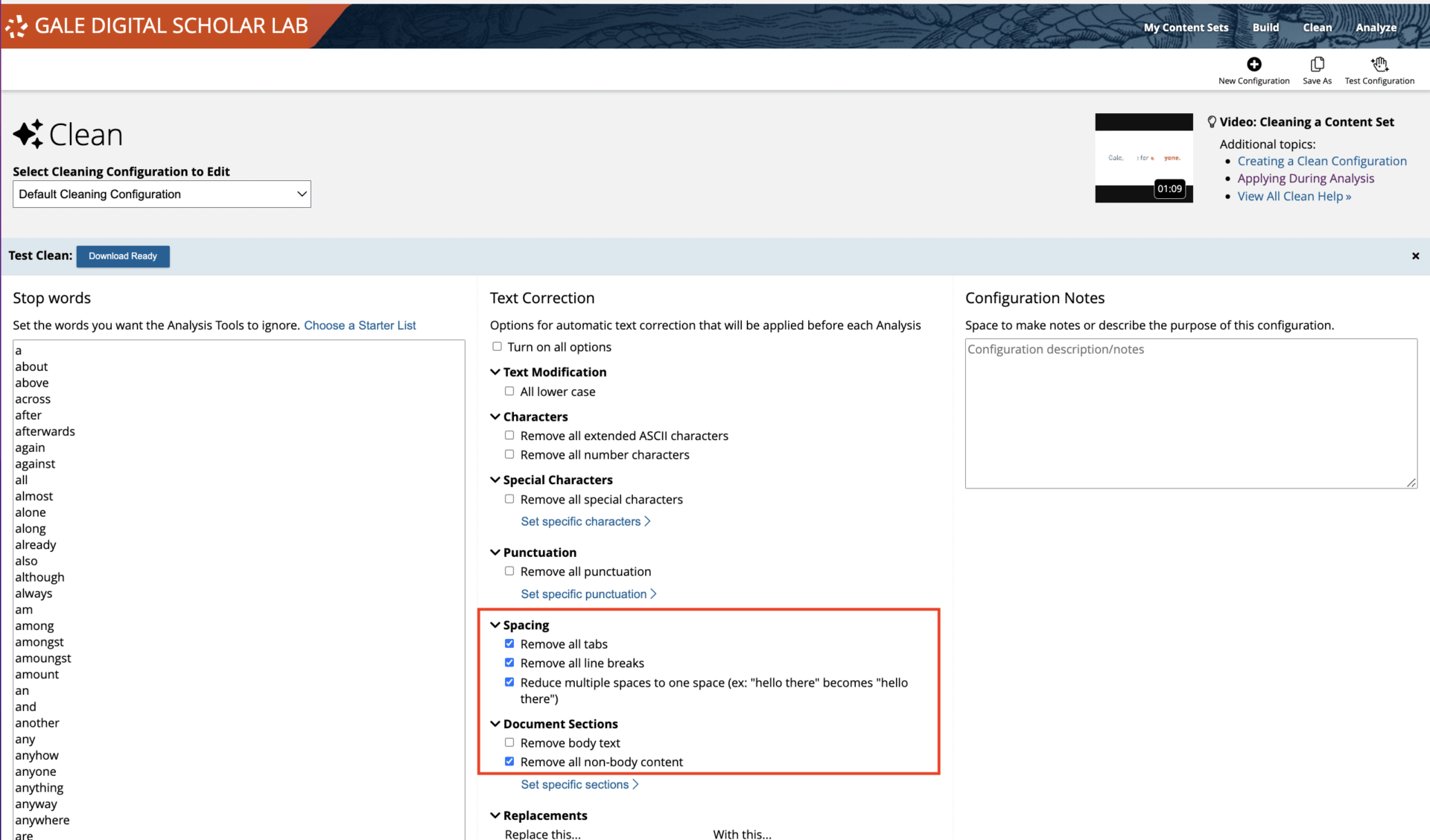
The ‘Clean’ tool is accessed via the main menu, and the user is presented with a variety of options to tackle recurrent textual errors and ‘pre-process’ the data before moving forward to analysis. One important consideration is setting up a process for documenting the changes made to the original dataset. This is a best practice for preserving and disseminating data. The Lab provides a ‘Configuration Notes’ field which can be completed as you make your cleaning choices, but you could equally make notes in a separate document for inclusion in the final project documents.
Getting Started
The Default Clean will remove all tabs, line breaks, and will reduce multiple spaces to one space (i.e. normalizing whitespace). It will also remove all non-body content from a text such as the title page, front matter, table of contents, index and so on.
The Sequence of Cleaning Actions in the Lab
It is worth developing an understanding of how the Lab orders the processes of cleaning text when you make your selections. Below is a basic breakdown of the order of application; you may find that it is helpful to apply cleaning choices in stages for optimal precision.
Stage I:
- Select desired text segments from document(s).
What is cleaned is based on your search results, and the document or section of a document which you have added to your Content Set. This could be an entire monograph, or a single newspaper article.
Stage II:
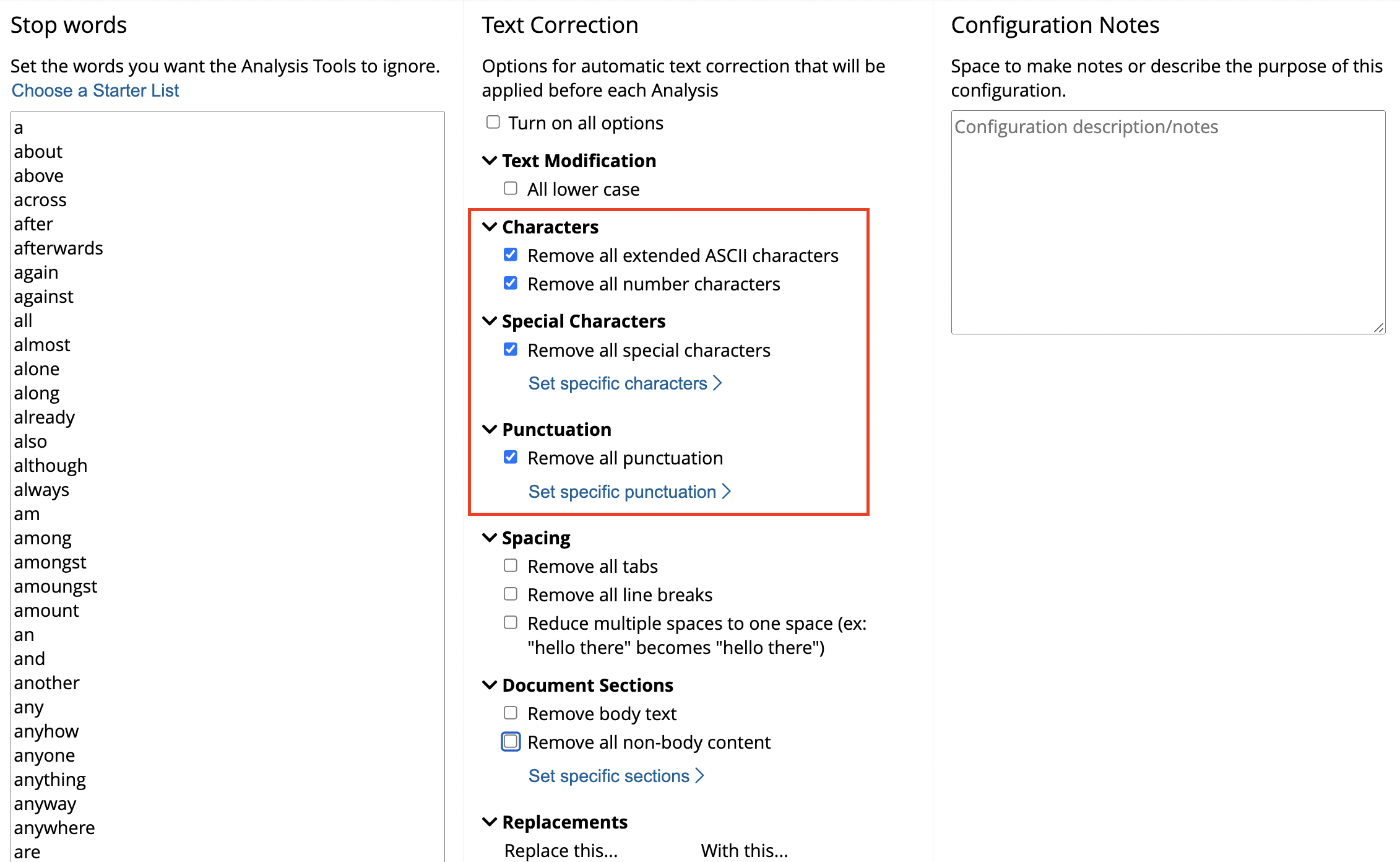
- Apply extended ASCII character filter.
- Apply character drops, if any, or in other words, remove special characters, punctuation, etc.
Stage III:
- Apply ReplaceWiths, if any.
This is applied in the text sequence.
(For example, if one were to replace ‘thb’ (OCR error) with ‘the’, and then apply the Stop Words, it would replace the error, then remove all occurrences of ‘the’ including the error.)

Stage IV:
- Apply Stop Word filter, if any.
Note that it is possible to choose a starter list in multiple languages.
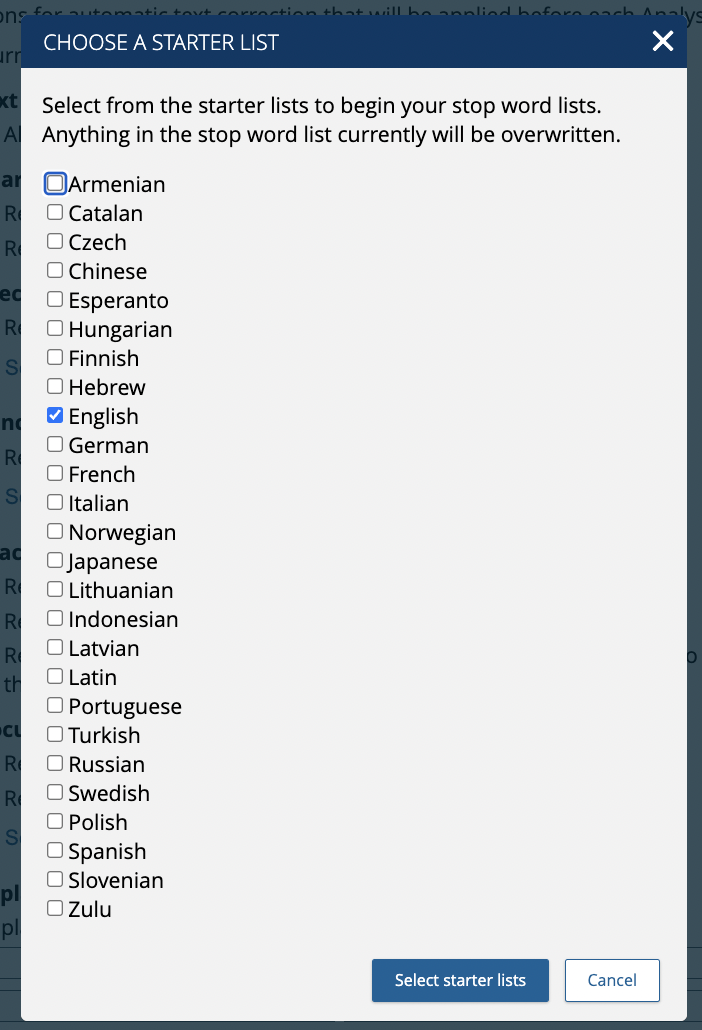
- Apply multi-space normalization to single spaces, if enabled.
- Apply lower-case, if enabled.
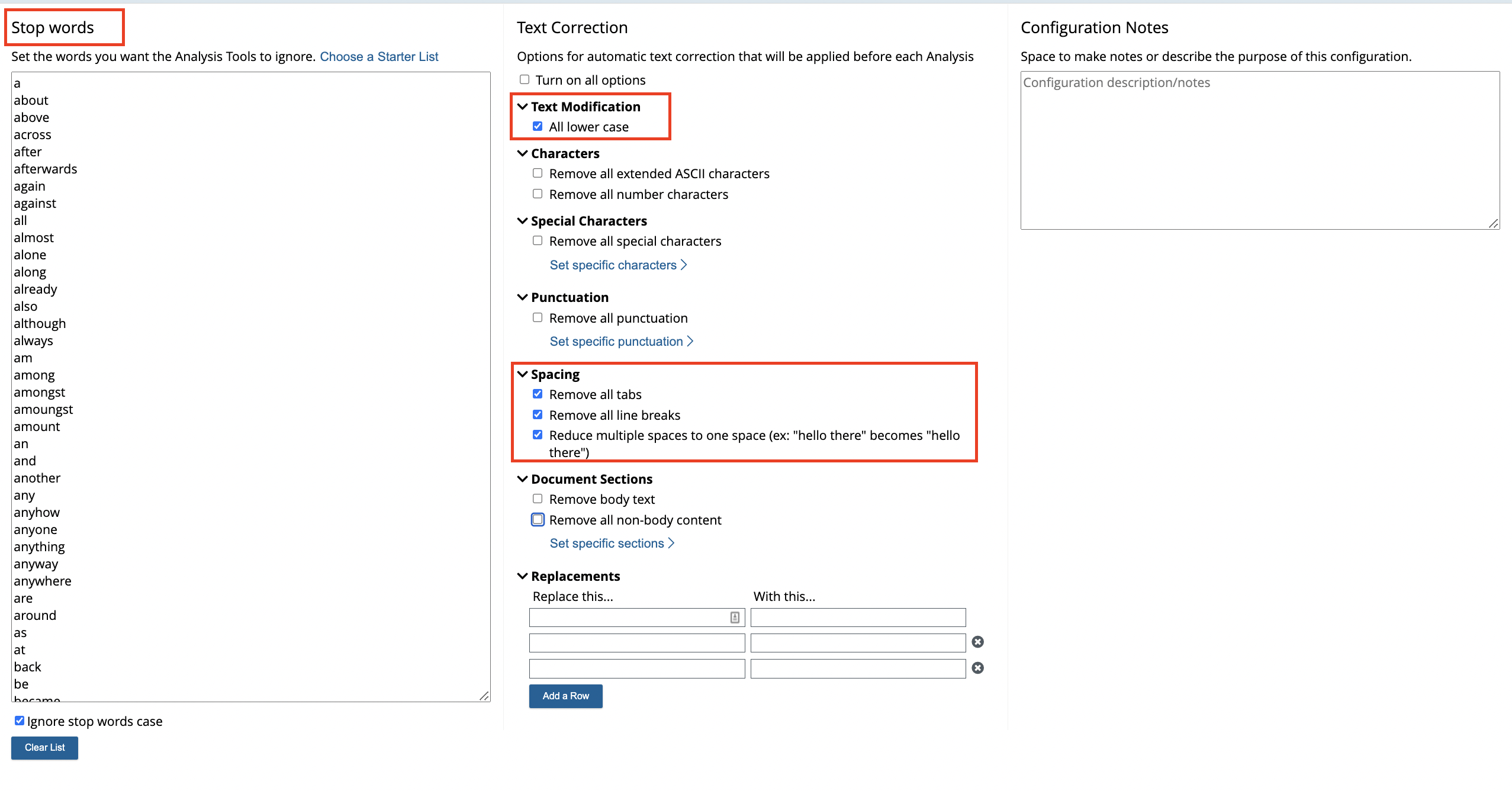
What comes out of Stage IV in the cleaning sequence is what is sent to all the selected analysis jobs which have the specific Clean Configuration applied. None of the analysis tools have access to original document text in this case.
If you want the tools to run on the original uncorrected documents, then choose ‘no clean’ during the analysis setup.
Tool-Specific Considerations When Creating a Clean Configuration
It is important to note that the clean configuration choices you make will impact certain tools in specific ways. This is detailed in the Lab’s Learning Center documentation and is reproduced here.
Topic Modelling
MALLET, the software powering the Topic Modelling Tool, is case sensitive. If you decide to make everything lower case, it cannot distinguish between Smith (a family name) and smith (an occupation, like a blacksmith). MALLET also handles possessive apostrophes by turning them into their own words. To change this, you can add ’s to the Stop Word list to prevent this from happening.
Parts of Speech
The Parts of Speech tagger is powered by spaCy, an open-source library for Natural Language Processing. SpaCy processes an unstructured text (e.g., an OCR document), to render a linguistically annotated or tagged object. If the unstructured text is stripped of important features, such as prepositions, conjunctions, and/or punctuation, spaCy will not be able to discern syntactical and grammatical relationships. The takeaway here is that better results are achieved for Parts of Speech analysis by using an empty Stop Words list.
Sentiment Analysis
Gale Digital Scholar Lab uses the AFINN Lexicon to analyse the sentiment score of your documents. The AFINN Lexicon contains a list of tokens from a specified language. If you add to the Stop Word list any words that are likewise part of the Sentiment Lexicon, these words will not be factored into the sentiment analysis. The default Stop Word List words does not contain any words that make the AFINN Sentiment Lexicon. If you create your own Stop Word List, check to make sure that any of the words do not exist in the AFINN Lexicon.
Ngram
The Ngram tool, and many others, Tokenize, or cut up, documents according to the whitespaces within the text. Therefore, it’s prudent to replace all tabs or other characters that might have slipped by the OCR processing with single spaces to make sure that documents are tokenized appropriately. Because of this, we have pre-selected the whitespace options in our Default Configuration (see above). You can change these if you prefer to do so.
Cleaning Your Data is Almost Always Iterative
It is worth making the point that the Clean stage of data curation can be very slow and is almost always iterative. Developing an understanding of the stages of the process and specific tool requirements can help frame the development of your initial cleans, alongside documentation of the choices you have made. The Gale Digital Scholar Lab enables users to download a sample of 10 cleaned documents, with the same 10 uncleaned documents, to test the configuration and determine what further cleaning refinements will be needed, if any. This testing can be carried out at any stage of the decision-making process and is a useful checkpoint for researchers.
The Lab interface is flexible enough to provide a straightforward pathway for users to apply several clean configurations (and tool setups) to any given Content Set, enabling useful comparison between outputs. Should users need even more granular control of the clean-up process, Lab users can download up to 5000 documents of OCR text from any given Content Set to work with outside the platform. You can download these text files with your Lab cleans applied, or with no cleaning at all, and then continue the process locally. The Lab then provides a pathway to re-upload this plaintext material for further analysis and visualization.
If you enjoyed reading this month’s instalment of “Notes from our DH Correspondent,” try:
- Creating an Export Workflow with Gale Digital Scholar Lab
- Practical Pedagogy with Gale Digital Scholar Lab, Part I: Developing Your Syllabus and Learning Objectives
- Practical Pedagogy with Gale Digital Scholar Lab, Part II: Approaches to Project-Based Teaching and Learning
- A Sense of Déjà vu? Iteration in Digital Humanities Project Building using Gale Digital Scholar Lab
{kind=link}