
│By Sarah L. Ketchley, Senior Digital Humanities Specialist│
Every March is Women’s History Month! In keeping with the themes of digital scholarship explored in the ‘Notes from our DH Correspondent’ series, and to celebrate a lesser-known historical female figure, in this month’s post I’ll discuss how I am exploring some of my text research data using a new enhancement to Gale Digital Scholar Lab’s embedded analysis pathways.
Three new Python Notebooks (available from March 28th) offer researchers a way to analyse their data using annotated code blocks which can be run using an interactive coding platform like JupyterLab or Google CoLab. These Notebooks offer flexible customisation options, such as the ability to process downloaded Datasets from within the Lab, or to run the user’s own datasets. Three Notebooks are available: Named Entity Recognition, Geographical Information System (GIS), and Sentiment Analysis. We’ll explore the NER Notebook in this post, and discuss additional workflows and output using the GIS and Sentiment Analysis Notebooks in a future post.
Introducing Mrs. Emma B. Andrews

As an Egyptologist, I have been researching the disciplinary history of the field for more than a decade. My interest was piqued when I first encountered the diaries of Mrs. Emma B. Andrews, who was the companion of Theodore M. Davis, a well-known and somewhat controversial figure in Egyptian archaeological circles during the so-called ‘Golden Age of Egyptology’ in the late nineteenth and early twentieth centuries.
Mrs. Andrews kept a diary of her Nile travels each year, between 1889-1913. She was a sharp-eyed witness to many significant discoveries in the Valley of the Kings, and her record provides a fascinating glimpse into the social, political, and archaeological networks of the day. Her descriptions of the people and landscape of Egypt during her years of travel provide rich cultural context to her accounts.

Recognising the unique record Mrs. Andrews had created, four typewritten copies of her diaries were made in 1919 at the behest of the Curator of Egyptian Art at the Metropolitan Museum of Art in New York. The volumes have remained otherwise unpublished until I began working with the material in 2011 with undergraduate student interns. Our team has transcribed the scanned copies of all the journals into plaintext format, before encoding the texts into XML following a schema developed by the Text Encoding Initiative (TEI).
Our goal is to capture a subset of named entities in the text through our XML tagging work. We tag people’s names, place names, organisations, archaeological sites, boats, hotels, books, cultural institutions, and artwork. This information provides a starting point for targeted research on the history of the period, particularly the narratives of some of the ‘hidden figures’ of Egyptology, many of whom are women. We have used the tagged document to create an online immersive reader, combining our transcription with its underlying TEI/XML text and a dynamic sidebar providing biographies and geographical information about the people and places in the text.

Extracting Named Entities Using a Python Notebook
Of course, tagging with XML is just one way to capture and extract named entities from transcribed primary source texts. As well as a suite of six tools embedded in the platform, Gale Digital Scholar Lab now provides a set of three downloadable Python Notebooks combining annotated instructions and Python code for flexible processing and analysing of text outside the Lab. The Named Entity Recognition Notebook leverages the SpaCy NER model to parse a text or folder of texts and return a list of named entities specified by the researcher.
After downloading the Notebook to my local machine, I opted to run the code as a Google Colab Notebook by simply uploading the .ipynb file from the Lab.
The default entity provided in the Notebook is PlaceName, and so I began by adding my folder of nineteen diary volumes into my Colab workspace, then followed the directions to install the necessary dependencies so I could process my texts. The output once exported as a CSV file looks something like this:
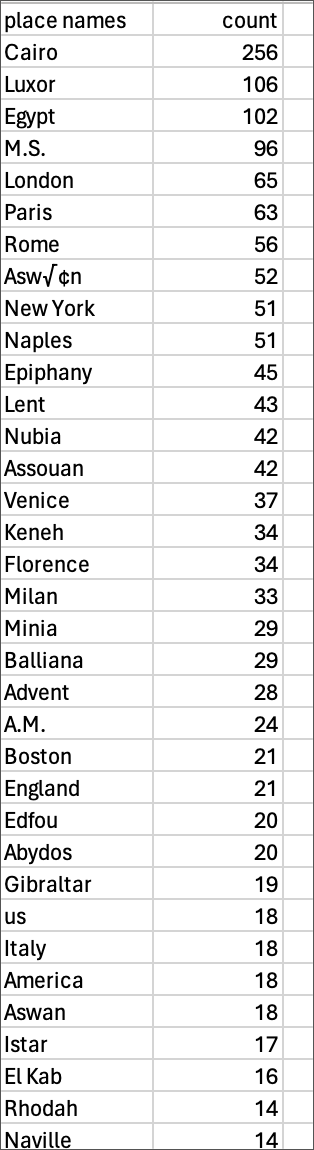
The structure is simple (place name and number of times mentioned), but the data provides a starting point to gain insights into the text. There are a few miscategorized names, but the majority are correct. Which sites were most popular? Which countries did the party visit? My likely next step will be to run NER, choosing to focus on Time/Date entities, combined with Place Names. This methodology will provide a useful pathway to building interactive timelines of who was in which location, on what date.
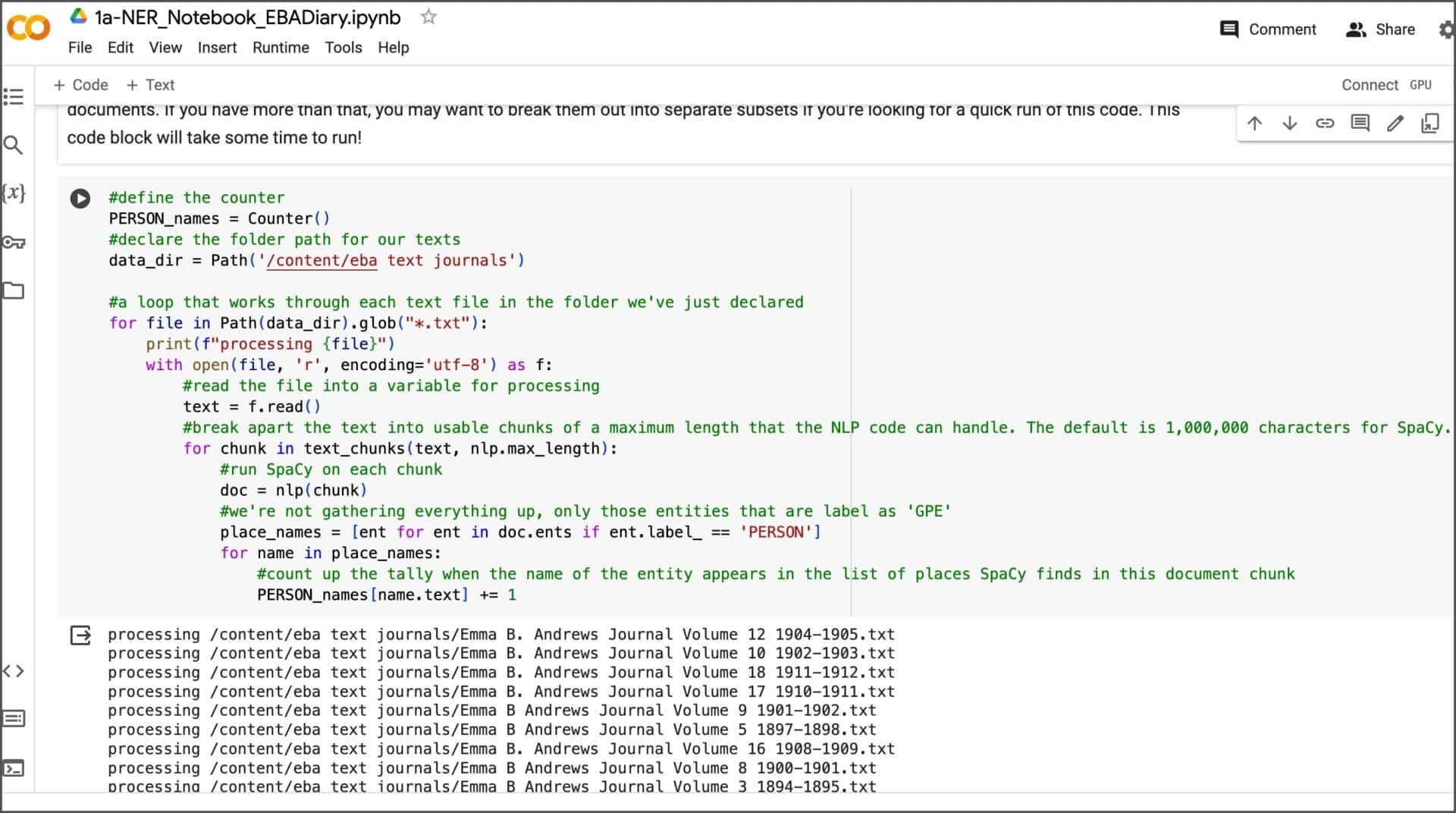
I also opted to run a Person name entity search on my nineteen volumes of text as well. To do this, I simply replaced the Place Name with Person in the code and re-ran the code block. The process of implementing the counter looks something like this:
And once the text has been processed, the output list looks like this:
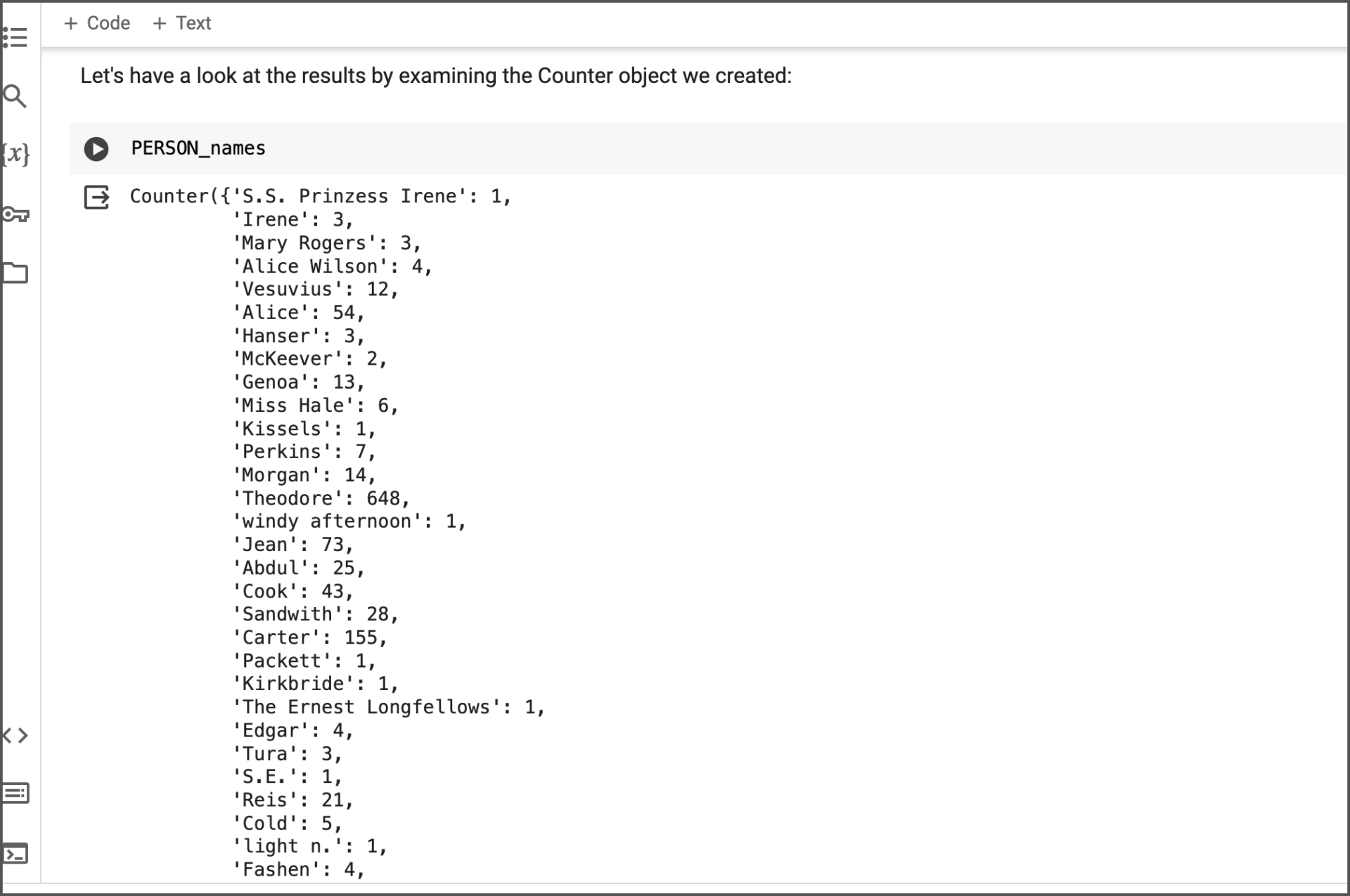
There’s obvious clean-up work to be done, but the Python Notebook provides tips on how to clean and correct OCR-text to help refine analysis output. Once this is done, the results can be structured in a CSV format for review.
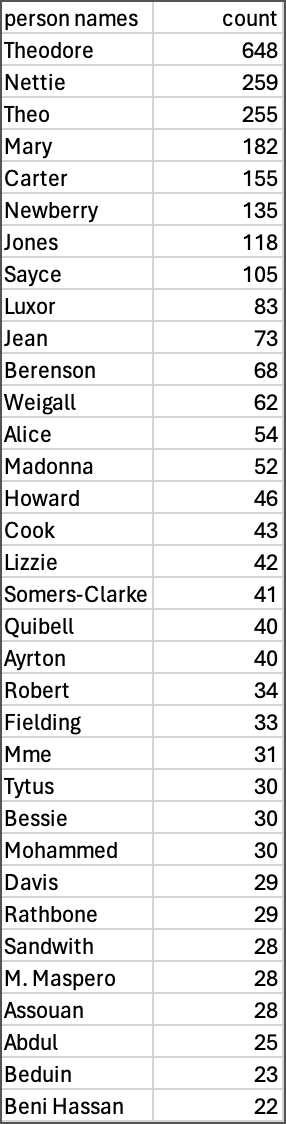
Working with the Output
I intend to use the NER Person name output to guide me in mapping out the development of biographical content for the immersive reader. To date, we have identified well over one thousand unique names mentioned by Mrs. Andrews in her diaries. Choosing a smaller subset to research is challenging, but in reviewing the NER Notebook output, it becomes obvious which person names were the most popular and deserving of our focus.
Conclusion
Nineteenth-century women are often invisible in the archives. Emma B. Andrews and many of her female contemporaries living and working in Egypt are a case in point. Working computationally with the text of her diaries, and other archival material I’ve collected, has provided valuable research insights about the period based on the analysis of large collections of text data. This type of analysis isn’t possible using traditional close reading methods, and often prompts new research directions and discoveries.
If you enjoyed reading this blog post, check out others in the ‘Notes from our DH Correspondent’ series, which include:
{kind=link}