
│By Sarah L. Ketchley, Senior Digital Humanities Specialist│
Getting to grips with the scope and content of a digital primary source archive held by an institution’s library can be daunting, particularly if the archive consists of thousands of documents in a variety of formats. For an individual researcher, the task of sifting through vast quantities of data in the quest for material that is relevant for a particular research topic is something that can take years to accomplish. This blog post will explore some of the ways a researcher can use Gale Digital Scholar Lab in conjunction with Gale Primary Sources as a platform for exploratory analysis to gain insights into the topics and themes represented in a chosen archive.

What archives can I work with?
As well as being a robust platform for data analysis and visualization, Gale Digital Scholar Lab can also be used to access and analyze Gale archives, as well as user-uploaded plain text content. Using digital tools in an exploratory manner enables the researcher to sort the text data into smaller groups of thematically similar material. This serves the dual purpose of familiarizing the scholar with the research content, which helps them make effective choices for developing a research pathway.
Researchers often ask which databases are available for them to work with via their institution’s library website. These will usually be listed in the ‘library databases’ section and accessed via institutional authentication. Once logged into Gale Digital Scholar Lab, users can access a full list of their institution’s Gale Primary Sources by clicking on the ‘What Texts are Available’ link on the Home Page:
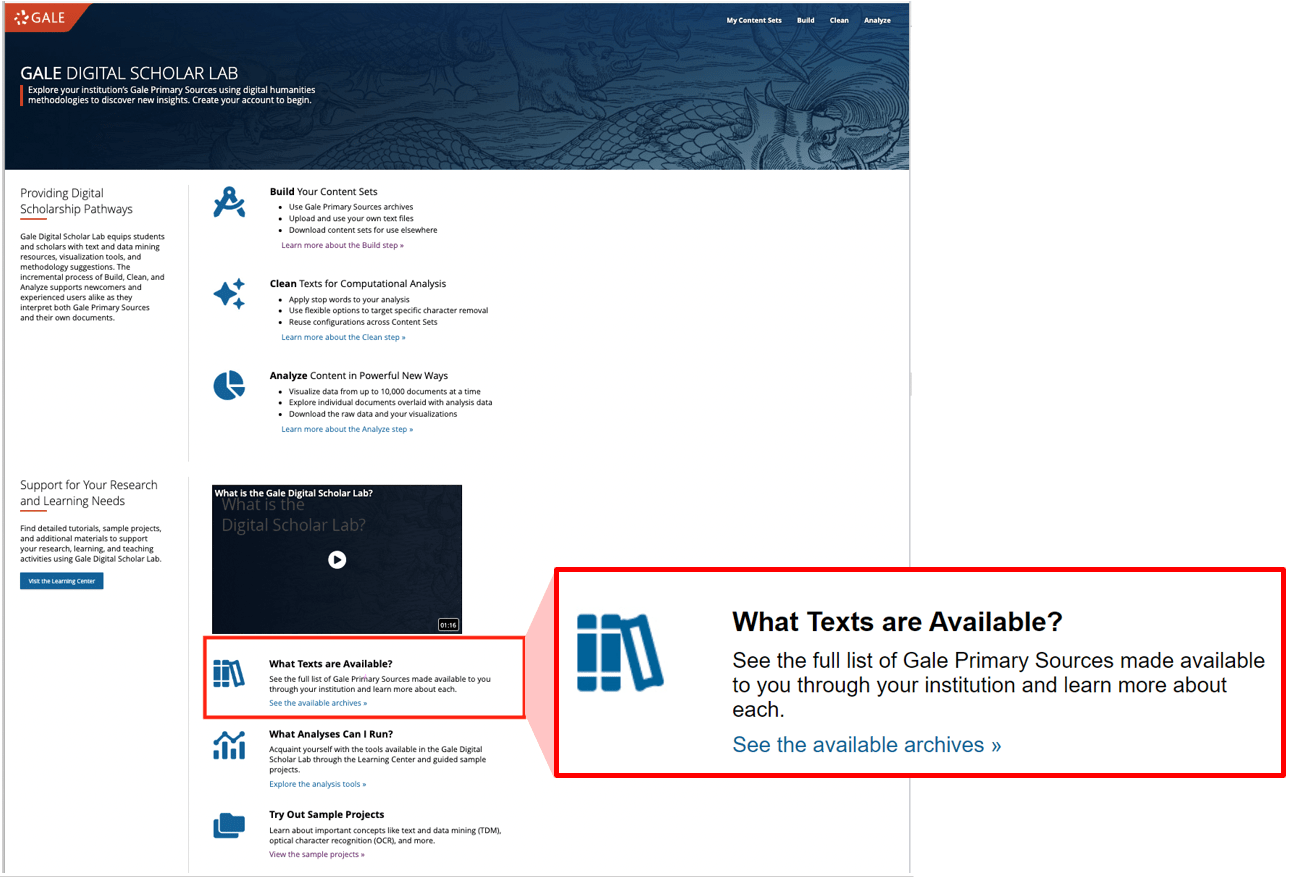
Clicking on the link enables a user to see a list of all the archives they can work with in the Gale Digital Scholar Lab. They can then search directly within individual archives from this page, or from the ‘Build’ page.
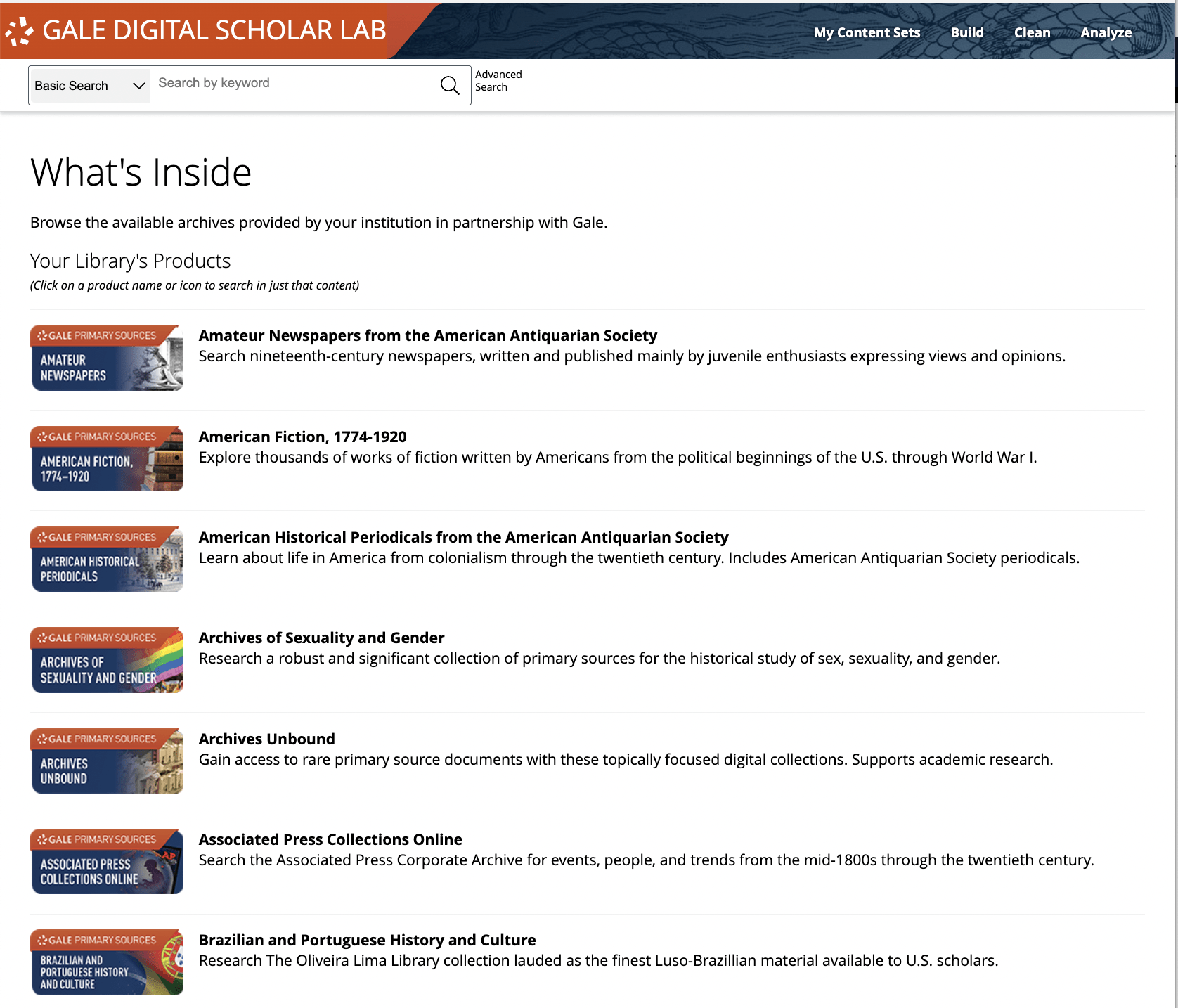
How can I figure out what’s in an archive without reading every page?
A good way to determine if archival content might be relevant for research is to use the tools in Gale Digital Scholar Lab to identify prevalent themes and topics. Doing this can provide guideposts to significant or pertinent documents, while also suggesting material to discard from any potential research Content Set.
The starting point for this type of investigation is to create a new Content Set from a discrete Gale Primary Sources archive. In this post, I’ll be exploring themes in the Making of the Modern World Part IV archive. Using the Advanced Search, it’s possible to limit by database, so in my case I deselected all archives except for Making of the Modern World, then I further limited by module. I ended up with 9,016 items in the Content Set I created from this initial search, which will offer significant insights into the scope of the archive.
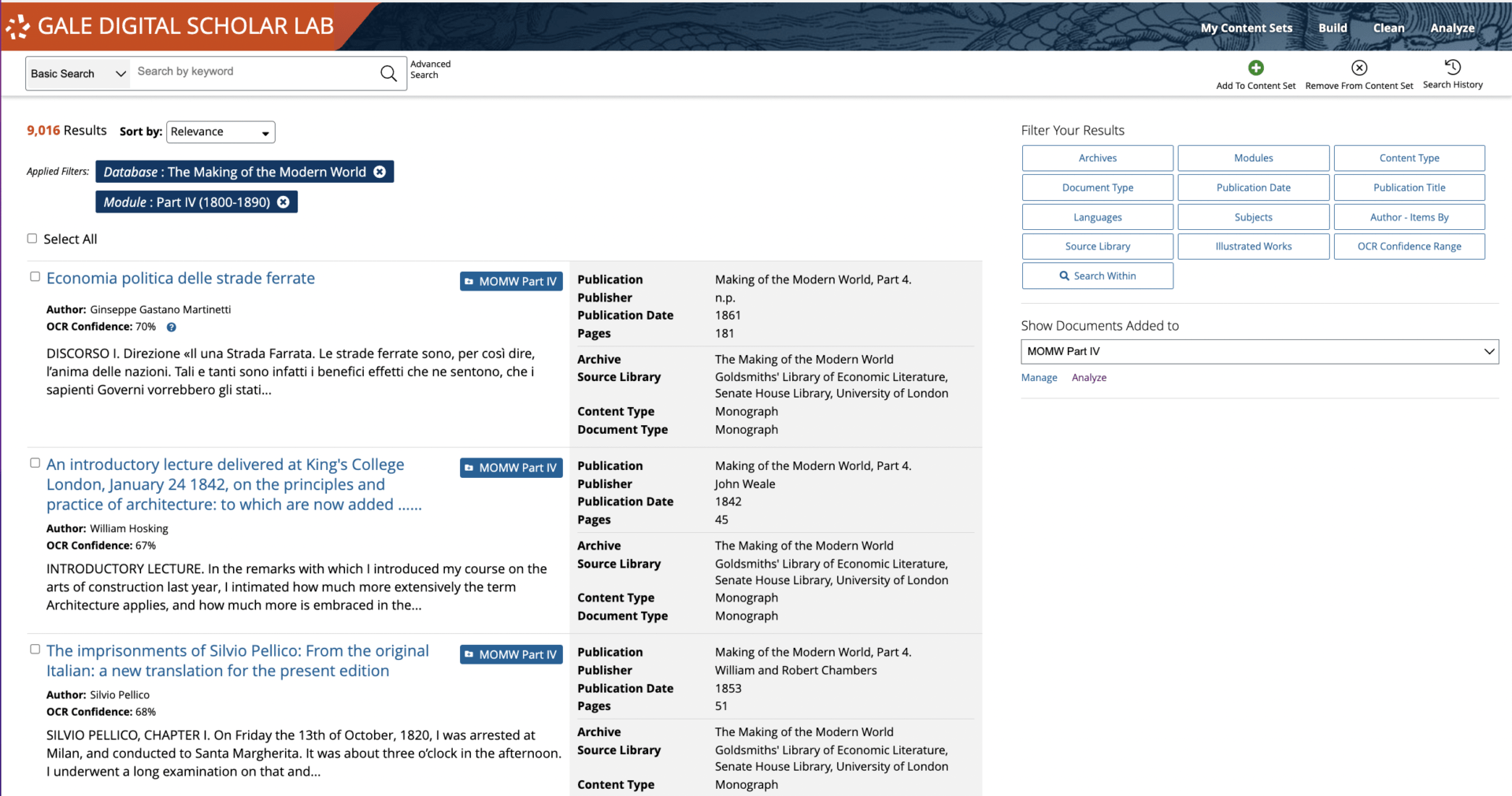
Topic Modelling
Having created my Content Set, I opted to run a topic modelling analysis consisting of 20 topics with 15 words per topic, using Gale’s Default Cleaning Configuration. This removes all tabs, line breaks, normalizes white space and removes all non-body content in the text. While the default topic model returns 10 topics, choosing 20 provides a more granular overview of the dataset, while remaining manageable for the researcher. In this case, there were obvious grouped themes in the Making of the Modern World Part IV data, including groups related to education, temperance, industry, finances, trade, as well as collected documents in non-English languages including French, German, Spanish, Italian and Latin. The language groupings were a good way to begin segmenting out what I did want to work with further, while highlighting material that could be usefully removed.
The screenshot below shows the renaming process underway. Initial results will be named ‘Topic 0’ through ‘Topic 19’ and it is the researcher’s job to identify the connection the algorithm is making to generate each topic, then rename it appropriately. ‘Topic 4’ was thus renamed ‘Education and childhood’ since the words in the topic were ‘work, children, school, number, years, schools, poor, education, cases, relief, year, men, persons, Act, London’. Going through this process can be a good way to gain familiarity with the primary source data.

Clustering
The Clustering tool can be used in a similar way. The image below shows the Making of the Modern World Part IV Content Set grouped into 20 clusters of related topics. The visualization is interactive, so as a researcher moves their mouse over the points on the chart, they will see the titles of individual documents within the cluster. The outliers are also worth investigating to determine how they are related – if at all – to the other material in the Content Set. Clicking into individual clusters will open a panel on the right-hand-side of the screen where the researcher can examine the data at document level. Again, this provides an opportunity to gain familiarity with clusters of related material. Clustering also provides a pathway to segment related groups of documents into a new Content Set, so even at this preliminary stage, the Gale Digital Scholar Lab facilitates discovery and effective organization of research data.

Using the ‘My Content Sets’ overview for research orientation
Each Content Set has an ‘Overview’ page in the ‘My Content Sets’ area of the Lab. This provides a range of useful information, including the document types represented in the collected material, along with the authors and the timeframe. This breakdown can provide some guidance as to logical ways to divide up the data either for further curation or for analysis. For example, ‘the Temperance Society’ is one of the authors listed in the Making of the Modern World Part IV Content Set, a distinct group which could be split into a separate Content Set, within the broader Making of the Modern World folder of data.
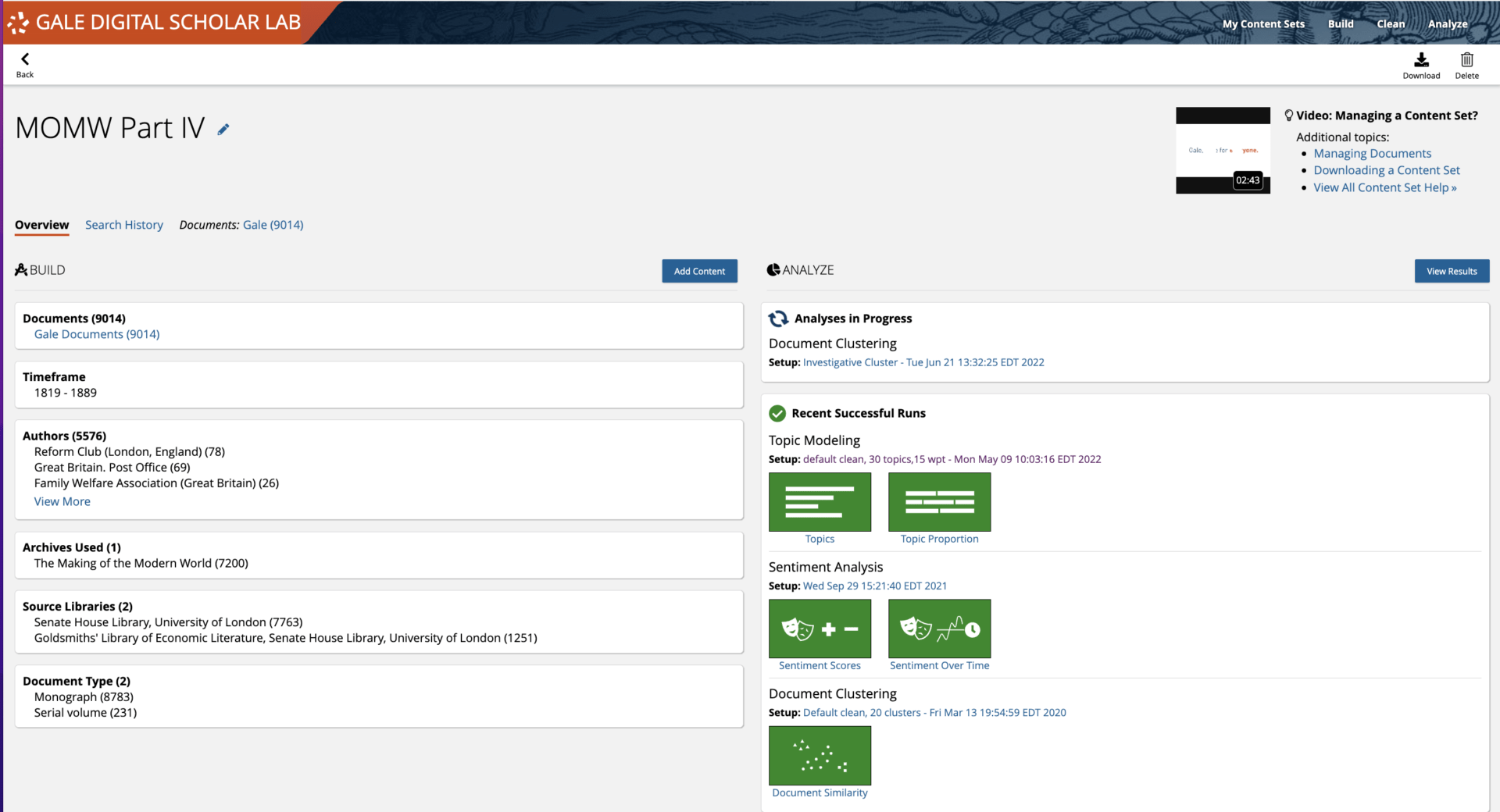
After the initial exploration
Once you have completed your initial text data exploration, you can begin the process of conducting targeted analysis on the texts you have designated as most relevant for your research questions. This will likely involve ongoing data curation, text cleaning and a combination of distant and close reading of texts. Conducting an exploratory analysis can provide a useful jumping off point for this type of work.
You can learn more about the archive and the process of identifying themes in Making of the Modern World Part IV in this video:
If you enjoyed reading this month’s instalment of “Notes from our DH Correspondent,” try:
- Doing the Digital Laundry? Notes on Cleaning Unstructured Text Data
- Creating an Export Workflow with Gale Digital Scholar Lab
- Practical Pedagogy with Gale Digital Scholar Lab, Part I: Developing Your Syllabus and Learning Objectives
- Practical Pedagogy with Gale Digital Scholar Lab, Part II: Approaches to Project-Based Teaching and Learning
- A Sense of Déjà vu? Iteration in Digital Humanities Project Building using Gale Digital Scholar Lab
{kind=link}