
│By Alan Thomas, AI Research Engineer at the Centre for Machine Intelligence, University of Sheffield│
Poor optical character recognition (OCR) quality is a major obstacle for humanities scholars seeking to make use of digitised primary sources such as historical newspapers. To improve the quality of noisily OCR’d historical documents, we introduce BLN600 – an open-access dataset derived from Gale’s British Library Newspapers – and showcase the potential of large language models (LLMs) for post-OCR correction using Llama.
Background
Digital archives have become an indispensable resource for humanities research. Primary sources such as newspapers, early printed books, and handwritten documents have been digitised and preserved in searchable online databases such as Gale’s British Library Newspapers using OCR technology to convert scanned images of historical documents into machine-readable text.
However, a persistent challenge faced by scholars seeking to make use of these resources is the low quality of transcriptions produced by OCR. Due to the age and condition of the original documents, the OCR process often results in inaccurate transcriptions, creating obstacles for researchers who rely on these texts for their work.

At the Centre for Machine Intelligence at the University of Sheffield, we are working on a collaborative project with the Digital Humanities Institute that aims to address this issue by applying advanced artificial intelligence methods to improve the quality of OCR transcriptions for historical documents. In this blog, we detail how LLMs can be used for post-OCR correction, which involves refining and correcting the textual output produced by OCR technology.
BLN600 – An Open-Source Dataset
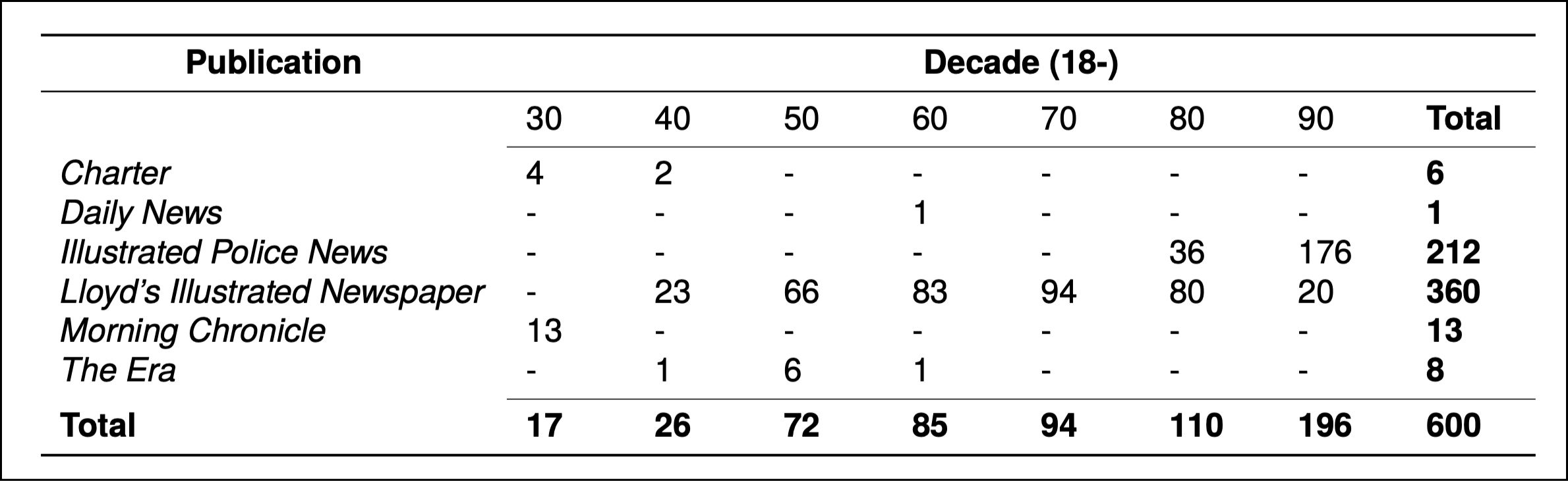
Improving OCR quality, especially for historical documents, remains a significant challenge with limited publicly available resources. To address this, we released BLN600, a publicly available parallel corpus of nineteenth-century newspaper text, focused on crime in London. This corpus is derived from Parts I and II of Gale’s British Library Newspapers collection. BLN600 comprises 600 newspaper excerpts, each containing the original source image, a machine-generated OCR transcription, and a manually created gold standard transcription.

British Library Newspapers spans over 200 years of British newspaper history, featuring more than 240 different publications. To curate BLN600 from this extensive archive, we conducted a custom query to identify crime-related articles published in London-specific newspapers, yielding 10,000 full-page images. From these, we randomly selected 600 images based on the presence of crime-related content and the readability of the text. Each image was manually rekeyed by humans and aligned with the corresponding OCR text from British Library Newspapers to produce a complete sample.
BLN600 is a valuable resource for historians and digital humanities researchers exploring nineteenth-century crime journalism by providing gold-standard transcriptions that facilitate the application of NLP (natural language processing) techniques. The source images allow researchers to use BLN600 as a benchmark dataset for tracking and measuring improvements in OCR engine performance for historical documents. Parallel OCR text and ground truth can be used to support the development and training of post-OCR correction models.
Post-OCR Correction With LLMs
Llama is a family of pre-trained and fine-tuned LLMs (large language models) released by Meta AI. The fine-tuned chat model is designed for assistant-like chat and optimised for dialogue applications, similar to ChatGPT. The pre-trained base model is a causal language model, designed to predict the next word in a sequence, which can be adapted for various natural language generation tasks including post-OCR correction. We opted to use Llama 2 due to its open-access nature and availability of various versions.
Using BLN600, we created a dataset of sequence pairs by dividing the text into segments, which can be sentences, short titles, or longer passages. After generating these pairs, we split them into training and evaluation sets. The training set is used to build an instruction-tuning dataset, featuring instruction, input, and response fields to guide the model’s response.
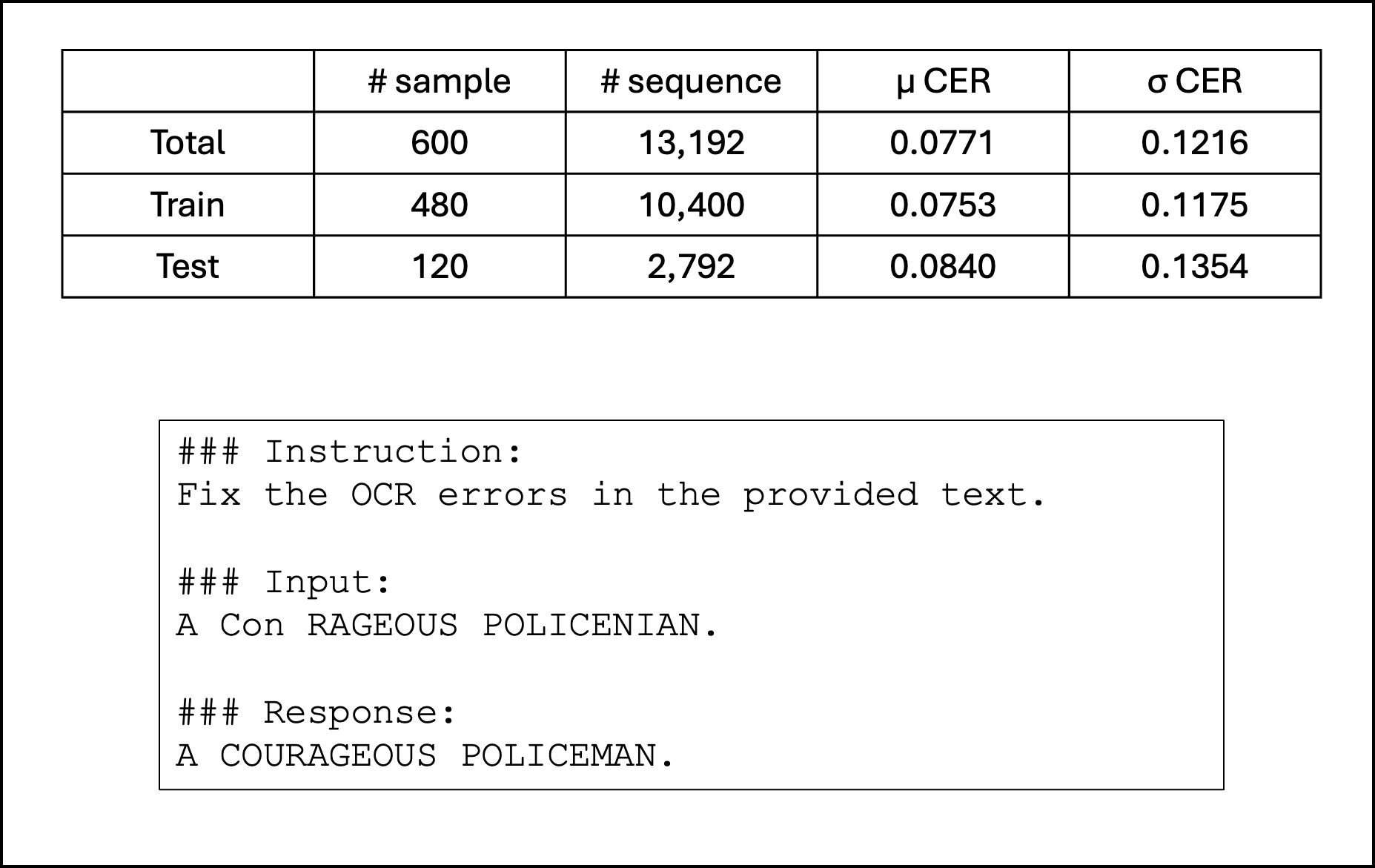
After fine-tuning the base Llama 2 model on our instruction-tuning dataset, it can be used to generate error corrections over the evaluation set. To measure the performance of our models, we compute the percentage reduction in character error rate. Character error rate (CER) measures how often characters are incorrect in a transcribed text compared to the total number of characters. Llama 2 7B achieves a 43.26% reduction in CER, whilst Llama 2 13B achieves a 54.51% reduction in CER, suggesting that these models can roughly halve the number of errors in OCR text.
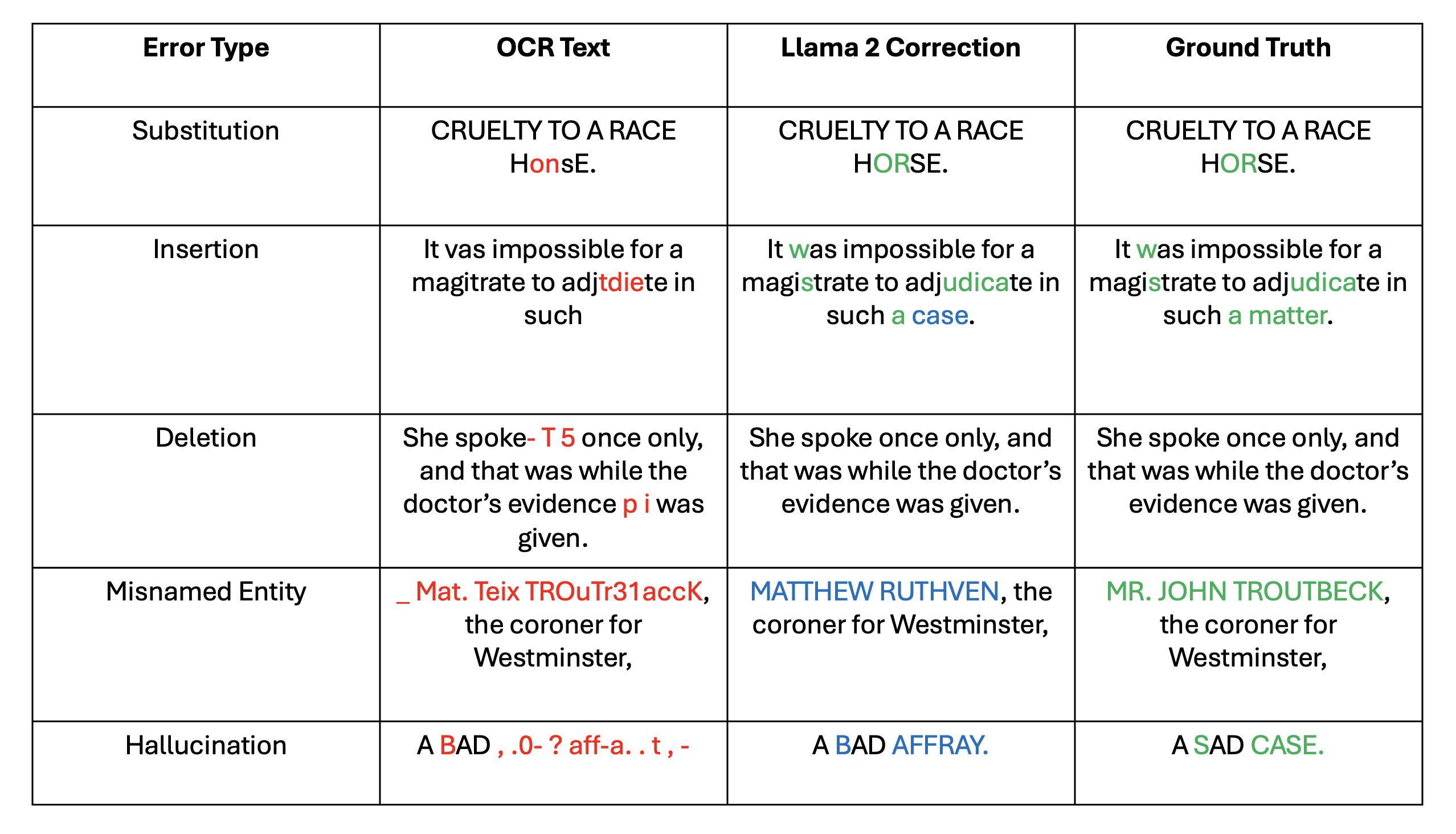
By employing LLMs for post-OCR correction, we can achieve a significant reduction in the number of errors in BLN600, paving the way for future work leveraging LLMs to improve the accessibility and unlock the full potential of historical texts for humanities research. Since the completion of this work, Llama 3 has been released with greater capabilities, indicating the potential for further improvement.
BLN600 is publicly accessible at https://doi.org/10.15131/shef.data.25439023.
For more details regarding this work, please refer to the following papers:
- Booth, Callum William, Alan Thomas, and Robert Gaizauskas. “BLN600: A Parallel Corpus of Machine/Human Transcribed Nineteenth Century Newspaper Texts.” Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources
- Thomas, Alan, Robert Gaizauskas, and Haiping Lu. “Leveraging LLMs for Post-OCR Correction of Historical Newspapers.” Proceedings of the Third Workshop on Language Technologies for Historical and Ancient Languages (LT4HALA)@ LREC-COLING-2024. 2024.
If you enjoyed reading about the use of AI to correct OCR, check out the ‘Notes from our DH Correspondent’ series, which includes:
- Coding for Humanists: Python Notebooks in Gale Digital Scholar Lab
- Playing Games with Data: Building Interactive Narratives with Twine
- Finding Meaning in K-Means: Clustering Analysis in Gale Digital Scholar Lab
- Building Projects in Gale Digital Scholar Lab
Blog post cover image citation: Montage of images in this blog post, combined with images from British Library Newspapers.
{kind=link}